Ill-posedness: An illustrative example
1D Inverse Heat Equation
An illustrative example of ill-posedness is the inversion for the initial condition for a one-dimensional heat equation.
Specifically, we consider a rod of length , and let denote the temperature of the rod at point and time . We are interested in reconstructing the initial temperature profile given some noisy measurements of the temperature profile at a later time .
Forward problem
Given
- the initial temperature profile ,
- the thermal diffusivity ,
- a prescribed temperature at the ends of the rod,
solve the heat equation
and observe the temperature at the final time :
Analytical solution to the forward problem
Verify that if
then
is the unique solution to the heat equation.
Inverse problem
Given the forward model and a noisy measurement of the temperature profile at time , find the initial temperature profile such that
Ill-posedness of the inverse problem
Consider a perturbation
where and .
Then, by linearity of the forward model , the corresponding perturbation is
which converges to zero as .
Hence the ratio between and can become arbitrary large, which shows that the stability requirement for well-posedness can not be satisfied.
Discretization
To discretize the problem, we use finite differences in space and Implicit Euler in time.
Semidiscretization in space
We divide the interval in subintervals of the same lenght , and we denote with the value of the temperature at point and time .
We then use a centered finite difference approximation of the second derivative in space and write
with the boundary condition .
We let be the number of discretization points in the interior of the interval , and let
be the vector collecting the values of the temperature at the points with .
We then write the system of ordinary differential equations (ODEs): where is the tridiagonal matrix given by
Time discretization
We subdivide the time interval in time step of size . By letting denote the discretized temperature profile at time , the Implicit Euler scheme reads
After simple algebraic manipulations and exploiting the initial condition , we then obtain
or equivalently
In the code below, the function assembleMatrix generates the finite difference matrix and the function solveFwd evaluates the forward model
from __future__ import print_function, absolute_import, division
import numpy as np
import scipy.sparse as sp
import scipy.sparse.linalg as la
import matplotlib.pyplot as plt
%matplotlib inline
def plot(f, style, **kwargs):
x = np.linspace(0., L, nx+1)
f_plot = np.zeros_like(x)
f_plot[1:-1] = f
plt.plot(x,f_plot, style, **kwargs)
def assembleMatrix(k, h, dt, n):
diagonals = np.zeros((3, n)) # 3 diagonals
diagonals[0,:] = -1.0/h**2
diagonals[1,:] = 2.0/h**2
diagonals[2,:] = -1.0/h**2
K = k*sp.spdiags(diagonals, [-1,0,1], n,n)
M = sp.spdiags(np.ones(n), 0, n,n)
return M + dt*K
def solveFwd(m, k, h, dt, n, nt):
A = assembleMatrix(k, h, dt, n)
u_old = m.copy()
for i in np.arange(nt):
u = la.spsolve(A, u_old)
u_old[:] = u
return u
A naive solution to the inverse problem
If is invertible a naive solution to the inverse problem is simply to set
The function naiveSolveInv computes the solution of the discretized inverse problem as
The code below shows that:
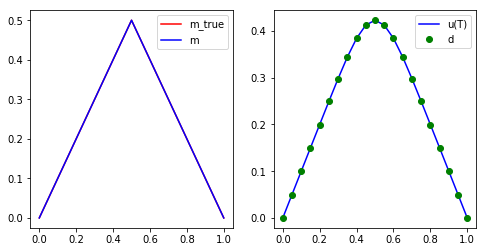
- for a very coarse mesh (
nx = 20) and no measurement noise (noise_std_dev = 0.0) the naive solution is quite good - for a finer mesh (
nx = 100) and/or even small measurement noise (noise_std_dev = 1e-4) the naive solution is garbage
def naiveSolveInv(d, k, h, dt, n, nt):
A = assembleMatrix(k, h, dt, n)
p_i = d.copy()
for i in np.arange(nt):
p = A*p_i
p_i[:] = p
return p
T = 1.0
L = 1.0
k = 0.005
print("Very coarse mesh and no measurement noise")
nx = 20
nt = 100
noise_std_dev = 0.
h = L/float(nx)
dt = T/float(nt)
x = np.linspace(0.+h, L-h, nx-1) #place nx-1 equispace point in the interior of [0,L] interval
m_true = 0.5 - np.abs(x-0.5)
u_true = solveFwd(m_true, k, h, dt, nx-1, nt)
d = u_true + noise_std_dev*np.random.randn(u_true.shape[0])
m = naiveSolveInv(d, k, h, dt, nx-1, nt)
plt.figure(figsize=(8,4))
plt.subplot(1,2,1)
plot(m_true, "-r", label = 'm_true')
plot(m, "-b", label = 'm')
plt.legend()
plt.subplot(1,2,2)
plot(u_true, "-b", label = 'u(T)')
plot(d, "og", label = 'd')
plt.legend()
plt.show()
Very coarse mesh and no measurement noise
print("Fine mesh and small measurement noise")
nx = 100
nt = 100
noise_std_dev = 1.e-4
h = L/float(nx)
dt = T/float(nt)
x = np.linspace(0.+h, L-h, nx-1) #place nx-1 equispace point in the interior of [0,L] interval
m_true = 0.5 - np.abs(x-0.5)
u_true = solveFwd(m_true, k, h, dt, nx-1, nt)
d = u_true + noise_std_dev*np.random.randn(u_true.shape[0])
m = naiveSolveInv(d, k, h, dt, nx-1, nt)
plt.figure(figsize=(8,4))
plt.subplot(1,2,1)
plot(m_true, "-r", label = 'm_true')
plot(m, "-b", label = 'm')
plt.legend()
plt.subplot(1,2,2)
plot(u_true, "-b", label = 'u(T)')
plot(d, "og", label = 'd')
plt.legend()
plt.show()
Fine mesh and small measurement noise
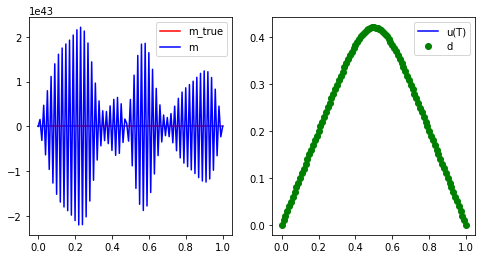
Why does the naive solution fail?
Spectral property of the parameter to observable map
Let with , then we have that
Note:
- Large eigenvalues corresponds to smooth eigenfunctions ;
- Small eigenvalues corresponds to oscillatory eigenfuctions .
The figure below shows that the eigenvalues of the continuous parameter to obervable map decays extremely (exponentially) fast.
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
T = 1.0
L = 1.0
k = 0.005
i = np.arange(1,50)
lambdas = np.exp(-k*T*np.power(np.pi/L*i,2))
plt.semilogy(i, lambdas, 'ob')
plt.xlabel('i')
plt.ylabel('lambda_i')
plt.title("Eigenvalues of continuous F")
plt.show()
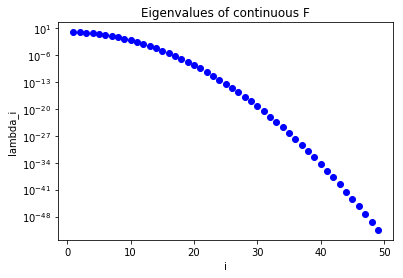
In a similar way, the figure below show the eigenvalues of the discrete parameter to observable map : their fast decay means that is extremely ill conditioned.
In the code below we assemble the matrix column-by-column, by computing its actions on the canonical vectors where the th entry is the only non-zero component of .
Disclaimer: is a large dense implicitly defined operator and should never be built explicitly for a real problem (since it would require evaluations of the forward problem and storage); instead — as you will learn later this week — scalable algorithms for the solution of the inverse problem only require the ability to compute the action of on a few given directions .
def computeEigendecomposition(k, h, dt, n, nt):
## Compute F as a dense matrix
F = np.zeros((n,n))
m_i = np.zeros(n)
for i in np.arange(n):
m_i[i] = 1.0
F[:,i] = solveFwd(m_i, k, h, dt, n, nt)
m_i[i] = 0.0
## solve the eigenvalue problem
lmbda, U = np.linalg.eigh(F)
## sort eigenpairs in decreasing order
lmbda[:] = lmbda[::-1]
lmbda[lmbda < 0.] = 0.0
U[:] = U[:,::-1]
return lmbda, U
## Compute eigenvector and eigenvalues of the discretized forward operator
lmbda, U = computeEigendecomposition(k, h, dt, nx-1, nt)
plt.semilogy(lmbda, 'ob')
plt.title("Eigenvalues of discrete F")
plt.show()
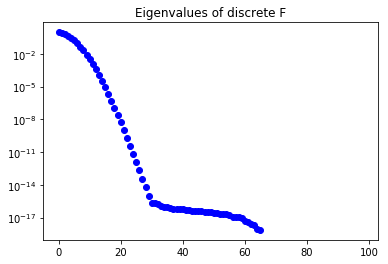
Informed and uninformed modes
The functions () form an orthonormal basis of .
That is, every function can be written as
Consider now the noisy problem
where
- is the data (noisy measurements)
- is the noise:
- is the true value of the parameter that generated the data
- is the forward heat equation
Then, the naive solution to the inverse problem is
If the coefficients do not decay sufficiently fast with respect to the eigenvalues , then the naive solution is unstable.
This implies that oscillatory components can not reliably be reconstructed from noisy data since they correspond to small eigenvalues.
Tikhonov regularization
The remedy is to find a parameter that solves the inverse problem in a least squares sense. Specifically, we solve the minimization problem
where the Tikhonov regularization is a quadratic functional of . In what follow, we will penalize the -norm of the initial condition and let . However other choices are possible; for example by penalizing the -norm of the gradient of (), one will favor smoother solutions.
The regularization parameter needs to be chosen appropriately. If is small, the computation of the initial condition is unstable as in the naive approach. On the other hand, if is too large, information is lost in the reconstructed . Various criteria — such as Morozov’s discrepancy principle or L-curve criterion — can be used to find the optimal amount of regularization (see the Hands on section).
Morozov’s discrepancy principle
The discrepancy principle, due to Morozov, chooses the regularization parameter to be the largest value of such that the norm of the misfit is bounded by the noise level in the data, i.e.,
where is the noise level. Here, denotes the parameter found minimizing the Tikhonov regularized minimization problem with parameter . This choice aims to avoid overfitting of the data, i.e., fitting the noise.
L-curve criterion
Choosing parameter using the L-curve criterion requires the solution of inverse problems for a sequence of regularization parameters. Then, for each , the norm of the data misfit (also called residual) is plotted against the norm of the regularization term in a log-log plot. This curve usually is found to be L-shaped and thus has an elbow, i.e. a point of greatest curvature. The L-curve criterion chooses the regularization parameter corresponding to that point. The idea behind the L-curve criterion is that this choice for the regularization parameter is a good compromise between fitting the data and controlling the stability of the parameters. A smaller , which correspond to points to the left of the optimal value, only leads to a slightly better data fit while significantly increasing the norm of the parameters. Conversely, a larger , corresponding to points to the right of the optimal value, slightly decrease the norm of the solution, but they increase the data misfit significantly.
Discretization
In the discrete setting, the Tikhonov regularized solution solves the penalized least squares problem
where denotes the Euclidean vector norm in .
can then be computed by solving the normal equations
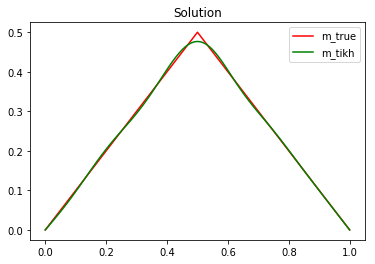
The code below, find the Tikhonov regularized solution for .
Disclaimer: In the code below, for simplicity, we explicitly construct and factorize the matrix . This approach is not feasible and should never be used to solve real problems (the computational cost is ). Instead, as we will see tomorrow, one should solve the normal equations using the conjugate gradient algorithm, which only requires the ability to compute the action of on a few given directions , and is guaranteed to converge in a number of iterations that is independent of .
def assembleF(k, h, dt, n, nt):
F = np.zeros((n,n))
m_i = np.zeros(n)
for i in np.arange(n):
m_i[i] = 1.0
F[:,i] = solveFwd(m_i, k, h, dt, n, nt)
m_i[i] = 0.0
return F
def solveTikhonov(d, F, alpha):
H = np.dot( F.transpose(), F) + alpha*np.identity(F.shape[1])
rhs = np.dot( F.transpose(), d)
return np.linalg.solve(H, rhs)
## Setup the problem
T = 1.0
L = 1.0
k = 0.005
nx = 100
nt = 100
noise_std_dev = 1e-3
h = L/float(nx)
dt = T/float(nt)
## Compute the data d by solving the forward model
x = np.linspace(0.+h, L-h, nx-1)
#m_true = np.power(.5,-36)*np.power(x,20)*np.power(1. - x, 16)
m_true = 0.5 - np.abs(x-0.5)
u_true = solveFwd(m_true, k, h, dt, nx-1, nt)
d = u_true + noise_std_dev*np.random.randn(u_true.shape[0])
alpha = 1e-3
F = assembleF(k, h, dt, nx-1, nt)
m_alpha = solveTikhonov(d, F, alpha)
plot(m_true, "-r", label = 'm_true')
plot(m_alpha, "-g", label = 'm_tikh')
plt.title("Solution")
plt.legend()
plt.show()
Hands on
Problem 1: Spectrum of the parameter to observable map
Question a:
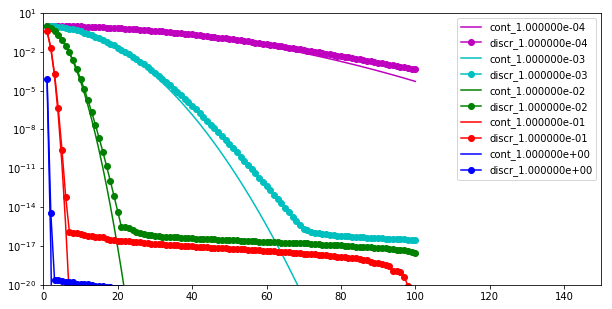
Set , , , and , and plot the decay of the eigenvalues of both the continuous () and the discrete () parameter-to-observable maps as a function of the index .
Do this for the following values of : 0.0001, 0.001, 0.01, 0.1, 1.0 (all on the same plot).
T = 1.
L = 1.
nx = 200
nt = 100
# Plot only the first 100 eigenvalues
i = np.arange(1,101)
colors = ['b', 'r', 'g', 'c', 'm']
plt.figure(figsize=(10,5))
for k in [1e-4, 1e-3, 1e-2, 1e-1, 1.]:
lambdas_continuous = np.exp(-k*T*np.power(np.pi/L*i,2))
lambdas_discrete, U = computeEigendecomposition(k, L/float(nx), T/float(nt), nx-1, nt)
lambdas_discrete = lambdas_discrete[0:len(i)]
c = colors.pop()
plt.semilogy(i, lambdas_continuous, '-'+c, label = "cont_{0:e}".format(k))
plt.semilogy(i, lambdas_discrete, '-o'+c, label = "discr_{0:e}".format(k))
plt.xlim([0, 150])
plt.ylim([1e-20, 10.])
plt.legend()
plt.show()
Question b:
Set , and ; plot the decay of the discrete eigenvalues as a function of for different resolutions in the space and time discretization.
Use .
What do you observe as you increase the resolution?
T = 0.1
L = 1.
k = 0.01
colors = ['b', 'r', 'g', 'c', 'm']
plt.figure(figsize=(10,5))
for (nx,nt) in [(20,20), (40,40), (80,80), (160,160)]:
lambdas_discrete, U = computeEigendecomposition(k, L/float(nx), T/float(nt), nx-1, nt)
c = colors.pop()
plt.semilogy(np.arange(1, nx), lambdas_discrete, '-o'+c, label = "{0:d}".format(nx))
plt.xlim([0, 200])
plt.ylim([1e-20, 10.])
plt.legend()
plt.show()
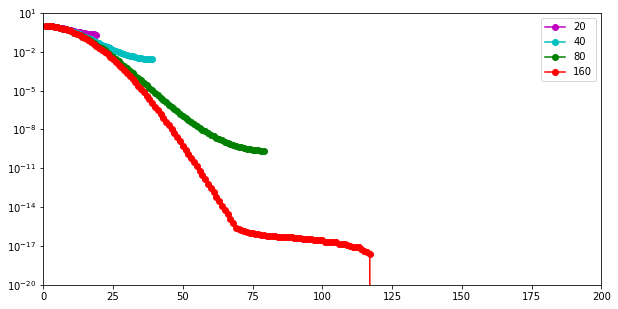
We note that the dominant (i.e. largest) eigenvalues are nearly the same at all levels of discretizations. Such eigenvalues are associated with smooth eigenvectors. As we refine the resolution of the discretization we are able to capture smaller eigenvalues, corresponding to highly oscillatory eigenvectors.
These spectral properties are common to many other discretized parameter-to-observable maps.
Problem 2: Tikhonov Regularization
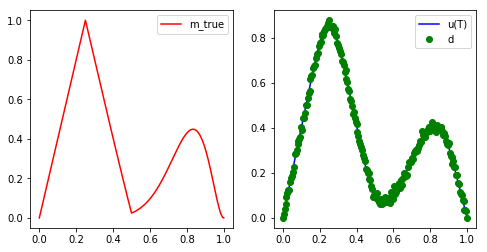
Consider the same inverse heat equation problem above with , , .
Discretize the problem using intervals in space and time steps.
As initial condition use the (discrete version of) the true initial temperature profile
Use the code below to implement the above function in Python:
import numpy as np
x = np.arange(1,n_x, dtype=np.float64)*h
m_true = np.maximum( np.zeros_like(x), 1. - np.abs(1. - 4.*x)) \
+ 100.*np.power(x,10)*np.power(1.-x,2)
Add normally distributed noise with mean zero and variance . The resulting noisy observation of the final time temperature profile is .
L = 1.
T = 0.1
k = 0.01
nx = 200
nt = 100
noise_std_dev = 1e-2
h = L/float(nx)
dt = T/float(nt)
## Compute the data d by solving the forward model
x = np.linspace(0.+h, L-h, nx-1)
m_true = np.maximum( np.zeros_like(x), 1. - np.abs(1. - 4.*x)) + 100.*np.power(x,10)*np.power(1.-x,2)
u_true = solveFwd(m_true, k, h, dt, nx-1, nt)
d = u_true + noise_std_dev*np.random.randn(u_true.shape[0])
plt.figure(figsize=(8,4))
plt.subplot(1,2,1)
plot(m_true, "-r", label = 'm_true')
plt.legend()
plt.subplot(1,2,2)
plot(u_true, "-b", label = 'u(T)')
plot(d, "og", label = 'd')
plt.legend()
plt.show()
Question a
Use Tikhonov regularization with to compute the regularized reconstructions .
F = assembleF(k, h, dt, nx-1, nt)
colors = ['b', 'r', 'g', 'c', 'm']
for alpha in [1e-4, 1e-3, 1e-2, 1e-1, 1.]:
m_alpha = solveTikhonov(d, F, alpha)
plot(m_alpha, "-"+colors.pop(), label = '{0:e}'.format(alpha))
plt.legend()
plt.title("m_alpha")
plt.show()
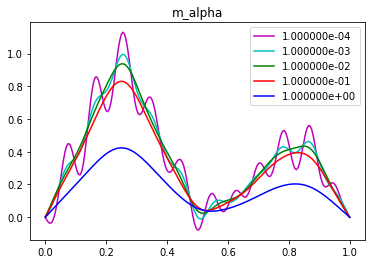
In the eye norm, the best reconstruction is for between and . For such values of the reconstructed solution well captures the smooth features of the true parameter, and it does not present spurious oscillations.
Question b
Determine the (approximate) optimal value of the regularization parameter in the Tikhonov regularization using the L-curve criterion.
norm_m = [] #norm of parameter
norm_r = [] #norm of misfit (residual)
for alpha in [1e-5, 1e-4, 1e-3, 1e-2, 1e-1, 1.]:
m_alpha = solveTikhonov(d, F, alpha)
norm_m.append( np.sqrt( np.dot(m_alpha,m_alpha) ) )
u_alpha = solveFwd(m_alpha, k, h, dt, nx-1, nt)
norm_r.append( np.sqrt( np.dot(d-u_alpha,d-u_alpha) ) )
plt.loglog(norm_r, norm_m, "-ob")
plt.xlabel("|| F m - d ||")
plt.ylabel("|| m ||")
plt.title("L-curve")
plt.show()
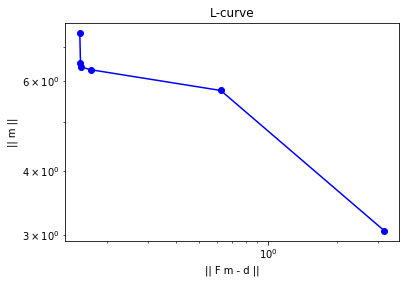
The elbow of the L-curve is located between and .
Question c
Determine the (approximate) optimal value of the regularization parameter in the Tikhonov regularization using Morozov’s discrepancy criterion, i.e., find the largest value of such that
where and is the solution of the Tikhonov-regularized inverse problem with regularization parameter .
alphas = [1e-5, 1e-4, 1e-3, 1e-2, 1e-1, 1.]
norm_r = [] #norm of misfit (residual)
for alpha in [1e-5, 1e-4, 1e-3, 1e-2, 1e-1, 1.]:
m_alpha = solveTikhonov(d, F, alpha)
u_alpha = solveFwd(m_alpha, k, h, dt, nx-1, nt)
norm_r.append( np.sqrt( np.dot(d-u_alpha,d-u_alpha) ) )
plt.loglog(alphas, norm_r, "-ob", label="||F m - d ||")
plt.loglog(alphas, [noise_std_dev*np.sqrt(nx-1)]*len(alphas), "-r", label="||n||")
plt.xlabel("alpha")
plt.legend()
plt.title("Morozov's discrepancy principle")
plt.show()
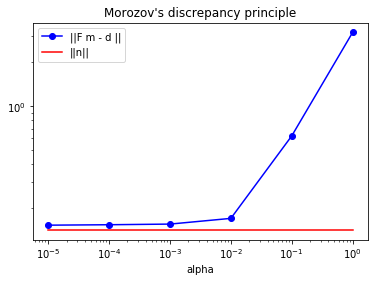
Since the noise is a i.i.d. Gaussian vector in with marginal variance , then we expect the to be of the order of .
The figure above compares the norm of the misfit (blue line) with (read line). The Morozov’s discrepancy principal then suggests that the optimal is near (i.e. where the two lines intersect).
Question d
Plot the norm error in the reconstruction, , as a function of , where is the Tikhonov regularized solution. Which value of (approximately) minimizes this error? Compare the optimal values of obtained using the L-curve and Morozov’s discrepancy criterion.
alphas = [1e-5, 1e-4, 1e-3, 1e-2, 1e-1, 1.]
err_m = [] #norm of misfit (residual)
for alpha in alphas:
m_alpha = solveTikhonov(d, F, alpha)
err_m.append( np.sqrt( np.dot(m_true-m_alpha,m_true-m_alpha) ) )
plt.loglog(alphas, err_m, "-ob", label="||m_true - m_alpha ||")
plt.xlabel("alpha")
plt.legend()
plt.title("Reconstruction error")
plt.show()
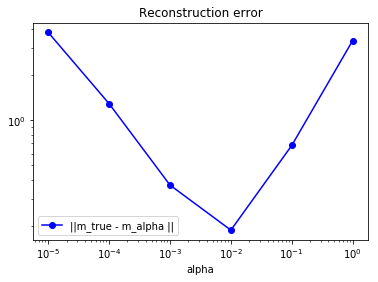
The obtained using the Morozov’s discrepancy principle is very close to the value of that minimizes the reconstruction error in the norm. The obtained using the L-curve criterion is smaller than the value of that minimizes the reconstruction error in the norm, thus indicating that the L-curve criterion underestimates the amount of regularization necessary for solving this inverse problem.
Problem 3: Tikhonov regularization on the gradient of
Consider the Tikhonov regularized solution where we penalize the norm of the gradient of . That is, solves minimization problem
Question a
Discretize and solve the inverse problem using the same parameters and true initial condition as in Problem 2.
L = 1.
T = 0.1
k = 0.01
nx = 200
nt = 100
noise_std_dev = 1e-2
h = L/float(nx)
dt = T/float(nt)
## Compute the data d by solving the forward model
x = np.linspace(0.+h, L-h, nx-1)
m_true = np.maximum( np.zeros_like(x), 1. - np.abs(1. - 4.*x)) + 100.*np.power(x,10)*np.power(1.-x,2)
u_true = solveFwd(m_true, k, h, dt, nx-1, nt)
d = u_true + noise_std_dev*np.random.randn(u_true.shape[0])
# Assemble the regularization matrix corresponding to the laplacian of m
R = -np.diag(np.ones(d.shape[0]-1), -1) + 2*np.diag(np.ones(d.shape[0]),0) - np.diag(np.ones(d.shape[0]-1), 1)
R*= h**(-2)
F = assembleF(k, h, dt, nx-1, nt)
def solveTikhonov2(d, F, R, alpha):
H = np.dot( F.transpose(), F) + alpha*R
rhs = np.dot( F.transpose(), d)
return np.linalg.solve(H, rhs)
colors = ['b', 'r', 'g', 'c', 'm']
for alpha in [1e-6, 1e-5, 1e-4, 1e-3, 1e-2]:
m_alpha = solveTikhonov2(d, F, R, alpha)
plot(m_alpha, "-"+colors.pop(), label = '{0:e}'.format(alpha))
plt.legend()
plt.title("m_alpha")
plt.show()
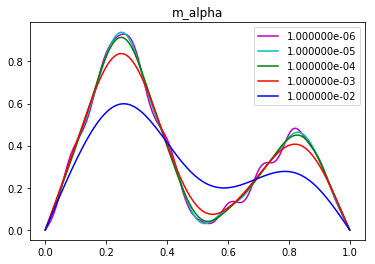
Question b
Determine the optimal amount of regularization using either the L-curve criterion or the discrepancy principle. How does this solution differs from the one computed in Problem 2?
alphas = [1e-7, 1e-6, 1e-5, 1e-4, 1e-3, 1e-2]
norm_r = [] #norm of misfit (residual)
for alpha in alphas:
m_alpha = solveTikhonov2(d, F, R, alpha)
u_alpha = solveFwd(m_alpha, k, h, dt, nx-1, nt)
norm_r.append( np.sqrt( np.dot(d-u_alpha,d-u_alpha) ) )
plt.loglog(alphas, norm_r, "-ob", label="||F m - d ||")
plt.loglog(alphas, [noise_std_dev*np.sqrt(nx-1)]*len(alphas), "-r", label="||n||")
plt.xlabel("alpha")
plt.legend()
plt.title("Morozov's discrepancy principle")
plt.show()
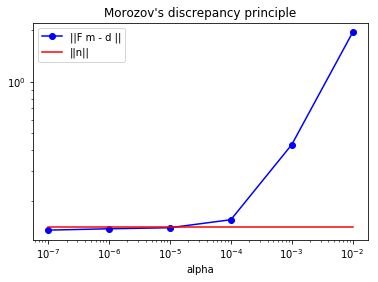
According to the Morozov’s discrepancy principle, should be chosen between and .
norm_m = [] #norm of parameter
norm_r = [] #norm of misfit (residual)
for alpha in [1e-9, 1e-8, 1e-7, 1e-6, 1e-5, 1e-4, 1e-3, 1e-2]:
m_alpha = solveTikhonov2(d, F, R, alpha)
norm_m.append( np.sqrt( np.dot(m_alpha,m_alpha) ) )
u_alpha = solveFwd(m_alpha, k, h, dt, nx-1, nt)
norm_r.append( np.sqrt( np.dot(d-u_alpha,d-u_alpha) ) )
plt.loglog(norm_r, norm_m, "-ob")
plt.xlabel("|| F m - d ||")
plt.ylabel("|| m ||")
plt.title("L-curve")
plt.show()
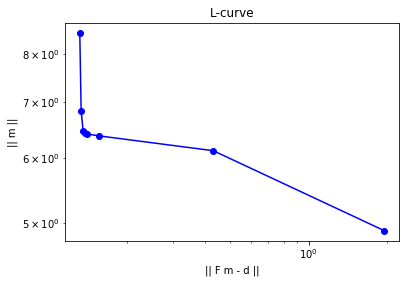
According to the Morozov’s discrepancy principle, should be chosen between and .
Copyright © 2018, The University of Texas at Austin & University of California, Merced. All Rights reserved. See file COPYRIGHT for details.
This file is part of the hIPPYlib library. For more information and source code availability see https://hippylib.github.io.
hIPPYlib is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License (as published by the Free Software Foundation) version 2.0 dated June 1991.